La sauvegarde de données, quelques généralités…
Mettre en œuvre une sauvegarde est indispensable pour plusieurs raisons: externaliser les données, restaurer un système complet, récupérer un document, … La situation idéale serait de ne perdre aucune donnée (valeur RPO proche de zéro) et d’avoir un arrêt de production le plus court possible (valeur RTO le plus proche possible de zéro). Des systèmes de réplication ou de sauvegarde continue, de basculement ou de reprise automatique répondent à ces problématiques. Voyons de plus près tout cela…
Depuis quelques années, les volumes à sauvegarder sont de plus en plus importants, on parle maintenant de plusieurs To (Téraoctets). Les temps de sauvegarde sont donc importants, et automatiquement la restauration également. Plus le temps de restauration est long, plus l’arrêt de production est important et impactera financièrement l’entreprise.
Il ne faut jamais négliger la sauvegarde à cause de considérations financières. Le coût d’une centaine de salariés au chômage technique, de pertes de transactions commerciales, d’une image de marque écornée, sera certainement supérieur à celui d’un dispositif de sauvegarde. Certains cabinets d’études statistiques mettent en avant le constat suivant: « une entreprise sur deux fermera ces portes dans les deux années à venir consécutif à un sinistre ayant entraîné une perte de données majeure ».
Une notion importante à ne pas négliger dans le monde de la sauvegarde est la Data Protection Windows (DPW) qui correspond au temps dont on dispose pour réaliser une sauvegarde consistante des données. En effet, si votre chaine de production ne s’arrête jamais, la DPW est nulle, et il faudra alors analyser des solutions telles que le CDP, réplication, …
Nous avons vu que certaines techniques comme les snapshots sont capables de réaliser une sauvegarde consistante. Si votre DPW est nul, mais qu’il vous est impératif de sauvegarder, les agents d’un logiciel de sauvegarde pourront réaliser une sauvegarde à chaud.
L’exemple le plus courant dans le monde Windows est l’agent de type Open Files (fichiers ouverts). En effet, si vous n’utilisez pas les clichés instantanés et que vous désirez sauvegarder un fichier ouvert, la sauvegarde n’en sera pas capable. Il faut avoir recourt à cet agent, spécialisé dans la sauvegarde à chaud de fichiers ouverts. Selon les logiciels de sauvegarde, les éditeurs disposent d’un catalogue plus ou moins étoffé d’agents disponibles pour des bases de données comme Oracle, DB2, etc…. Avant de choisir un logiciel de sauvegarde, assurez-vous qu’il est possible d’acquérir un agent spécifique pour votre applicatif.
Néanmoins en environnement virtualisé, la plupart des éditeurs commercialisent des agents spécifiques ou reposent sur les API des hyperviseurs. Ainsi, l’agent est capable non seulement de sauvegarder à chaud l’intégralité de la machine virtuelle mais également son contenu. Ainsi il est possible de restaurer l’intégralité d’une machine virtuelle à son emplacement d’origine ou sur un autre serveur, pour répondre à une problématique de RTO ou simplement de restaurer un fichier d’une machine virtuelle.
L’agent spécialisé dans la virtualisation permet d’économiser de l’argent car il intègre une « sorte » d’agent Open Files mais nécessite toujours des agents spécialisés pour Microsoft Exchange, par exemple. Des applications de sauvegarde dédiées à la sauvegarde d’hyperviseurs existent comme Veeam Backup, ou vRanger de VizionCore.
Comment calculer la fenêtre d’une sauvegarde, comment estimer l’espace de ma stratégie de sauvegarde, …. ? Autant de questions auxquelles les infrastructures de stockage de type SAN répondront. En effet, les stockages SAN nécessitent un réseau qui leur est propre et indépendant et surtout isolé du réseau de production. Abordé dans le chapitre C.1.C, l’environnement idéal d’une sauvegarde dans un environnement SAN est de créer un réseau dédié ou une zone afin de séparer les différents flux.
Calcul de taille d’une sauvegarde d’une machine virtuelle:
Taille de la sauvegarde = espace disque utilisé + mémoire vive (prévoir une marge de 10 %)
Calcul de taille d’une sauvegarde d’une machine virtuelle avec des clichés:
Taille de la sauvegarde = espace disque utilisé + mémoire vive + taille totale des clichés (prévoir une marge de 10 %)
Calcul de la taille d’une sauvegarde complète
Taille de la sauvegarde = espace disque utilisé * nombre de jours de rétention
Calcul de la taille d’une sauvegarde complète et incrémentale:
Taille de la sauvegarde = (espace disque utilisé * nombre de jours de rétention) + ((espace disque utilisé * taux de changement) * nombre de sauvegarde d’incrémentale)
Prenons l’exemple d’une librairie qui dispose des caractéristiques suivantes: un débit LTO4-HH théorique natif de 2.16 To/heure avec 3 lecteurs et de 4.32 To/heure. Le débit réaliste d’un lecteur LTO-4 est de 120 MB/s et dispose d’une capacité native de 800 Go sans compression. Nous devons sauvegarder 12 To d’un SAN en fibre optique et 1 To via un réseau Ethernet Gigabit.
La bande passante de la fibre optique 4 Gb est de 800 MB/s (en full duplex) soit 2.88 To par heure, donc dans notre exemple, le flux de sauvegarde ne saturera pas le réseau de stockage fibre optique. Le temps estimé sera de 12 To / 2.16 To/heure soit 25.92 heures en natif sans compression.
Pour sauvegarder 1 To (1000 Go) en Gigabit, la bande passante théorique est de 125 MB/s soit 450 Go/heure, mais partons plutôt sur un débit réaliste de 70 % soit environ 87.5 Mo/s ou encore 315 Go / heure. Le temps estimé de la sauvegarde par ce média sera de 1000 Go / 315 Go/heure soit 3.17 heures.
Une autre formule, plus réaliste que je vous recommande, tient compte des changements de cartouches au sein de la librairie:
Taille de la sauvegarde en Mo / débit de la sauvegarde en Mo/sec / 60 / 60 + (temps de changement de cartouche en minute(s) * nombre de cartouches utilisées)
Détail du calcul:
12000000 / 120 / 60 / 60 + (2 * (12000 Go / 800 Go)) soit 28h30 environ.
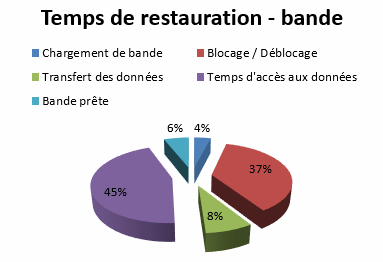
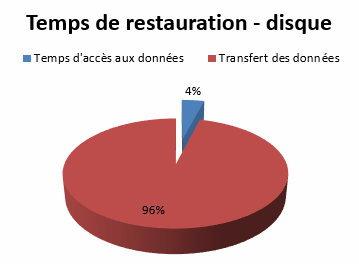
Alors que les lecteurs actuels dépassent le débit réalisable par les disques durs, leurs performances sont considérablement ralenties lors d’opérations de restauration dues aux opérations de chargement de la bande, de positionnement, … En réalité, les restaurations effectuées à partir de disques durs peuvent être de deux à dix fois plus rapide !
Le schéma suivant synthétise le découpage des temps d’un lecteur de bande pendant une opération de restauration. Le temps où le lecteur restaure les données ne représente que 8% du temps au total, le lecteur passant la plupart de son temps à des opérations non productives de chargement de média, de localisation des données sur la bande, ….
Si les disques accélèrent les temps de sauvegarde et de restauration, n’utiliser que ce média comporte des risques. La sauvegarde étant stockée sur un serveur relié au réseau, les données sont vulnérables aux virus, pannes disques, sinistre, … de plus, il sera très difficile de l’externaliser.
La sauvegarde disque doit être employée dans une stratégie disk-to-disk-to-tape (disque vers disque puis sur bande ou D2D2T), pour diminuer les temps de restauration et de sauvegarde ou lorsque celle-ci doit être déportée sur un autre site.
Bien entendu, les disques servant à héberger la sauvegarde peuvent être de type SATA à 7.200 tours par minutes, le flux étant séquentiel, ce type de disque correspond tout à fait à cet usage. Bien logiquement, la sauvegarde sur bande prends plus de temps qu’une sauvegarde sur disque, mais les clichés est la technique, à ce jour, qui dispose de la fenêtre la plus courte.
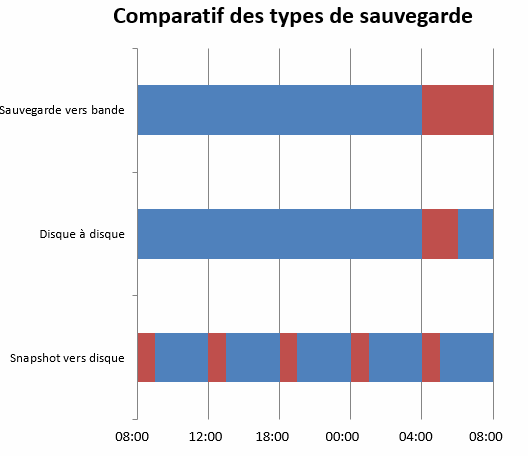
Les administrateurs de sauvegarde s’aperçoivent que la plupart des demandes de restauration concernent des données vieilles de 24 à 48 heures. La sauvegarde sur disque prend toute sa dimension dans ce cas de figure en adoptant la stratégie d’une rétention de 72 heures sur disque et au-delà un stockage sur bande.
On parle alors de Virtual Tape Library (VTL) qui sont en fait des Appliances dédiées aux opérations de sauvegarde sur disque qui émulent des lecteurs de bande de façon transparente pour les logiciels de sauvegarde.
L’avantage évident des Appliances VTL réside dans le fait qu’elles s’insèrent dans des environnements de librairies déjà en place sans remettre en cause la politique de sauvegarde et des investissements déjà réalisés. Techniquement les VTL permettent une augmentation des débits, une diminution des fenêtres de sauvegarde et du RTO tout en conservant une possibilité d’évolution de la capacité de sauvegarde par l’ajout de disques durs supplémentaires.
Il est possible de répliquer le contenu d’une VTL sur un autre site et bien entendu d’y adjoindre une solution de déduplication.
La Protection Continue (CDP)
Le CDP (Continuous Data Protection) représente une sauvegarde en continu dont le mécanisme est similaire à une réplication en temps réel en mode bloc ou en mode fichier pour certains logiciels. La technique consiste à capturer chaque changement en les copiant automatiquement vers un autre stockage et permet ainsi une restauration immédiate depuis n’importe quel moment dans le temps.
Certains éditeurs les appellent solutions de sauvegarde en temps réel ou sauvegarde continue permettant une restauration à n’importe quel moment dans le temps. Les avantages sont multiples, le RPO (Recovery Point Objective) est proche de zéro, suppression des fenêtres de sauvegarde, restauration immédiate, délocalisation de la sauvegarde sur un autre site, restauration d’une version non corrompue, …

Ce schéma illustre la différence entre une sauvegarde traditionnelle et continue. En environnement traditionnel, nous avons une perte de données (deux heures de RPO) entre la dernière sauvegarde et le moment où le désastre est intervenu. Suite à ce désastre, il convient de restaurer les données à partir de bandes, ce qui peut prendre beaucoup de temps (3h45 de RTO) selon la volumétrie. La sauvegarde continue est censée offrir un RTO de zéro, et le temps de restauration est quasi-instantané ou peut prendre quelques instants selon la volumétrie ou si il convient de rapatrier le snapshot depuis une autre baie, dans notre exemple l’arrêt de production (RTO) est de 10 minutes.
Il convient de noter qu’il existe deux variantes de ces solutions: le True CDP (le vrai CDP) et Near Continous (presque continu). La première peut assurer une restauration dans le temps quasi infinie grâce à une journalisation de chaque écriture en mode bloc contrairement à la dernière qui se base sur une planification à intervalle définie (toutes les quinze minutes, par exemple).
Là encore, il convient de connaître l’importance des données à sauvegarder, utiliser une protection de type True CDP pour des courriers électroniques serait surdimensionné, disposer d’une sauvegarde à la seconde est inutile pour un courriel, mais pour une base de données de commerce électronique, True CDP apporte de vrais arguments.
Le problème majeur du True CDP est qu’il ne connait pas en temps réel les changements de données qui interviennent sur le stockage tant que le cache n’est pas vidé (flush) vers les piles RAID. Pour contourner ce défaut, il conviendrait de vider le cache à tout moment, ce qui est impossible techniquement, ou alors si le cache du contrôleur de votre baie de stockage est paramétré en Write Thru, et encore.
Dans le monde UNIX, la commande SYNC permet de vider le cache manuellement, un certain nombre d’éditeurs ont porté l’outil sur d’autres plateformes. Cet outil s’utilisant de façon ponctuelle, il est difficilement envisageable de le mettre en œuvre avec une protection de type True CDP. Pour cette raison, un CDP doté d’une fenêtre de quelques minutes parait tout à fait convenable et réalisable.
Quelques acteurs du marché comme A-Tempo ou DataDomain répondent à des problématiques de sauvegarde continue. Le point le plus important à valider est la consistance des données éventuelles surtout en mode True CDP. En effet, True CDP capture chaque écriture sans ce souci d’un état cohérent de la donnée contrairement au Near CDP qui repose sur des snapshots planifiés (typiquement VSS pour Microsoft Data Protection Manager). Cependant, plusieurs éditeurs ont développé leur système en se reposant sur les API des éditeurs d’applications confirmant ainsi un état dit « application consistent » des sauvegardes.
La déduplication
La déduplication joue un rôle essentiel pour « lutter » contre l’explosion des données. Nous désirons tous obtenir une sauvegarde complète à tout moment mais il en résulte une capacité de sauvegarde qui croit de façon incroyable.
Lorsque l’on procède à une analyse des données, beaucoup d’entre elles sont redondantes. Nous nous accordons tous sur le fait que stocker un ou plusieurs fichiers est inutile et contre-productif. La première technique de déduplication à ne stocker qu’une seule fois un fichier était SIS (Single Instance Storage). Celle-ci est embarquée dans les systèmes d’exploitation Microsoft dédiés au stockage comme les versions Storage Server et Exchange. Sur le papier, cette technique est miraculeuse. Dans les faits, SIS agit au niveau fichier, ainsi une modification d’un seul mot dans un fichier de plusieurs Méga-Octets génère un nouvel enregistrement, et ne le considère pas comme un doublon.
Avec le logiciel de messagerie Exchange, SIS est implémenté au niveau du message, ce qui est beaucoup plus intéressant. Imaginez un responsable de service qui envoie une note de service de 10 Mo à l’ensemble de son service, soit 100 personnes. Un serveur de messagerie n’intégrant pas SIS stockera ainsi 1 Go d’espace disque pour le même courriel. Tandis qu’un système de messagerie incluant SIS ne stockera ce courriel qu’une seule fois, soit 10 Mo !
L’évolution du Single Instance Storage a mené à la déduplication. L’idée de cette technique est de générer des pointeurs vers un objet si nécessaire, c’est-à-dire que la donnée unique n’est stockée qu’une seule fois.
La déduplication agit au niveau bloc et découpe une donnée en de multiples tronçons grâce à un algorithme et à l’issue génère une signature unique qui sera stocké dans un index. Ainsi, lorsqu’un tronçon existe déjà dans l’index, un pointeur (sorte de lien symbolique) est généré dans le système de fichiers.
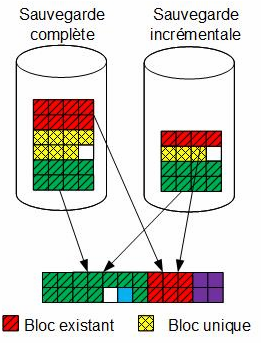
Prenons un exemple qui illustrera le schéma : un courriel de 10 Mo envoyé à 100 utilisateurs ne représentera que 10 Mo avec la technique de déduplication. On obtient un ratio de 100 :1 ce qui est énorme et le stockage ainsi économisé pour laisser entrevoir une politique de rétention beaucoup plus importante.
Etant donné que la déduplication agit au niveau bloc, contrairement au Single Instance Storage, un fichier qui subit une modification verra son nombre de blocs modifiés de façon insignifiante et pertinente. Par exemple, un fichier de 100 blocs qui subit une modification verra seulement 2 blocs de modifiés. D’un point de vue stockage, 98 blocs seront identiques et feront l’objet d’une création de pointeurs, et seuls 2 blocs seront réellement écrits.
La plupart des acteurs du marché utilise un hash MD5 ou SHA-1 comme algorithme pour générer des signatures. Le critère de performance d’une solution de déduplication réside dans l’algorithme qui va segmenter les données. Plus le découpage en segment d’une donnée est petit, plus le ratio que l’on pourra obtenir sera élevé. La taille des signatures doit être la plus réduite possible car plus la taille de votre index est importante, plus les temps pour savoir si un segment est unique ou non seront importants.
Selon les solutions de déduplication, la segmentation peut être déterminée automatiquement par l’algorithme (généralement des solutions haut de gamme et donc coûteuse) soit de façon fixe (8k par exemple) ou aléatoire. Les ratios annoncés par les éditeurs et constructeurs sont souvent impressionnants, mais dans la pratique il convient de diviser au moins par trois ou quatre les ratios annoncés.
Nous l’avons bien compris, la déduplication représente un avantage de taille dans le domaine de la sauvegarde sur disque. Mais le domaine où elle s’avèrera être la plus performante est la sauvegarde d’environnements virtuels. En effet, la plupart du temps, dans les centres de données, on dénombre entre deux à cinq systèmes d’exploitation différents. Si vous disposez au sein de votre datacenter de cinquante machines virtuelles Windows 2008 Service Pack 2, il est évident que plusieurs centaines de milliers fichiers, tels que des DLL (Dynamic Link Library) seront exactement les mêmes et seront donc très bien pris en compte par une solution de déduplication. Je vous recommande bien entendu d’avoir recours à un déploiement de vos systèmes d’exploitation effectué par l’intermédiaire de modèles (templates).
La déduplication apporte de nombreux avantages, dont le principal est d’économiser l’espace disque. Par déduction, votre stratégie de sauvegarde nécessitera moins de disques durs, donc une consommation électrique réduite, une fenêtre de sauvegarde amoindrie, une puissance en climatisation moindre, une occupation en nombre de U de vos baies en baisse.
Ces solutions sont disponibles sous forme de solution logicielle, de complément logiciel (plugin) ou d’Appliance dédiée. Beaucoup d’acteurs sont présents sur ce marché comme : Avamar, DataDomain, HP, FalconStor ou encore Bakbone.
La déduplication se déploie sous diverses formes : à la source, à la destination (target), en ligne (in-line) ou post-processus (back-end ou post-process). Voyons quelques scénarios d’applications avec les schémas suivants.
Afin d’augmenter la disponibilité des données, le contenu d’un serveur de déduplication peut être répliqué en vue d’être externalisé. Cela correspond tout à fait aux nouveaux usages tels que le Cloud Computing (infrastructure délocalisée sur internet). Le Cloud Computing reposant sur l’architecture internet, soit des bandes passantes faibles et non garanties, la déduplication du fait de son implémentation au niveau bloc, demeure une solution de premier ordre.
Les snapshots
Les snapshots, appelés clichés instantanés, constituent une copie en lecture seule des données à un instant donné (on parle de Point-In-Time) sans en interrompre l’accès avec un état de consistance de niveau application. Les clichés instantanés ne sont pas des sauvegardes à part entière, ils nécessitent pour restaurer des données la présence des données initiales. En revanche, il est possible de restaurer un cliché à un autre emplacement que celui d’origine, ce qui peut s’avérer être très pratique pour des tests applicatifs, par exemple.
Les snapshots représentent un excellent moyen de sécuriser les données sans pour autant être une sauvegarde à part entière, mais est le compagnon idéal d’une sauvegarde. Ainsi, il est possible de sauvegarder les clichés sur une bande à des fins d’externalisation.
Grâce à ce système de clichés, les stratégies de sauvegarde sont souvent remaniées en profondeur en entreprise. Ainsi, des clichés réalisés à plusieurs moments de la journée permettent de se rapprocher d’un RPO de zéro et qu’une sauvegarde sur bande des clichés diminue la fenêtre de sauvegarde.
Certains d’entre nous s’en servent comme de la pseudo-réplication en déclenchant un instantané de l’ensemble du volume pour le copier sur un autre stockage. L’espace disque consommé ne représentant que le delta des données modifiées, la bande passante requise reste faible et présente les caractéristiques d’une réplication asynchrone.
Le système de clichés peut être implémenté au niveau logiciel via Microsoft VSS, Linux LVM, VMware ou directement au niveau du stockage. Selon les systèmes d’exploitation et les baies de stockage, les snapshots peuvent être copiés d’une baie à une autre (intra-baie) ou d’un volume à un autre au sein d’un même stockage (inter-baie) et peuvent être à même d’agir au niveau fichier, LUN, volume, …
Le but des snapshots est d’obtenir un état consistant des données à un instant T. D’un point de vue logiciel, Microsoft VSS utilise les API Exchange, SQL, … la cohérence est donc garantie et la mise en œuvre demeure simple.
En revanche d’un point de vue matériel, obtenir un état consistant est beaucoup moins évident car certains constructeurs embarquent un système de cliché mais agissant uniquement au niveau du stockage, sans tenir compte des applications présentes. Donc, si vous utilisez un système d’exploitation du type Linux et une base de données Oracle, il vous faudra impérativement valider que votre baie de stockage dispose de mécanismes de clichés compatibles avec votre plateforme, SnapView de EMC est un exemple.

Je travaille actuellement en tant qu’Enterprise Architect pour le groupe CAPGEMINI. Acteur et expert communautaire reconnu depuis de nombreuses années, j’anime ce site autour des technologies Microsoft, des thématiques du Cloud, des infrastructures, … Je suis également à l’origine de nombreuses publications dans la presse IT.